AI That Knows Your Business and Acts On It
SerenityGPT turns your company knowledge into instant answers and intelligent automation. Connect your documentation, systems, and expertise — then let AI agents handle the workflows that slow your team down.






















Connect all of your data sources
Measurable Impact, Proven Results
70%+
↑ Automation Rate
Average time to answer employee questions
15+h/week
↑ Time Saved
Per employee on search and manual workflows
5< sec
↑ Response Time
Average time to answer employee questions
2< wks
↑ Deployment
From contract to production
Trusted by forward-thinking enterprises



Why Leading Companies Choose SerenityGPT
SerenityGPT is designed for day-to-day business work where accuracy, consistency, and control matter.
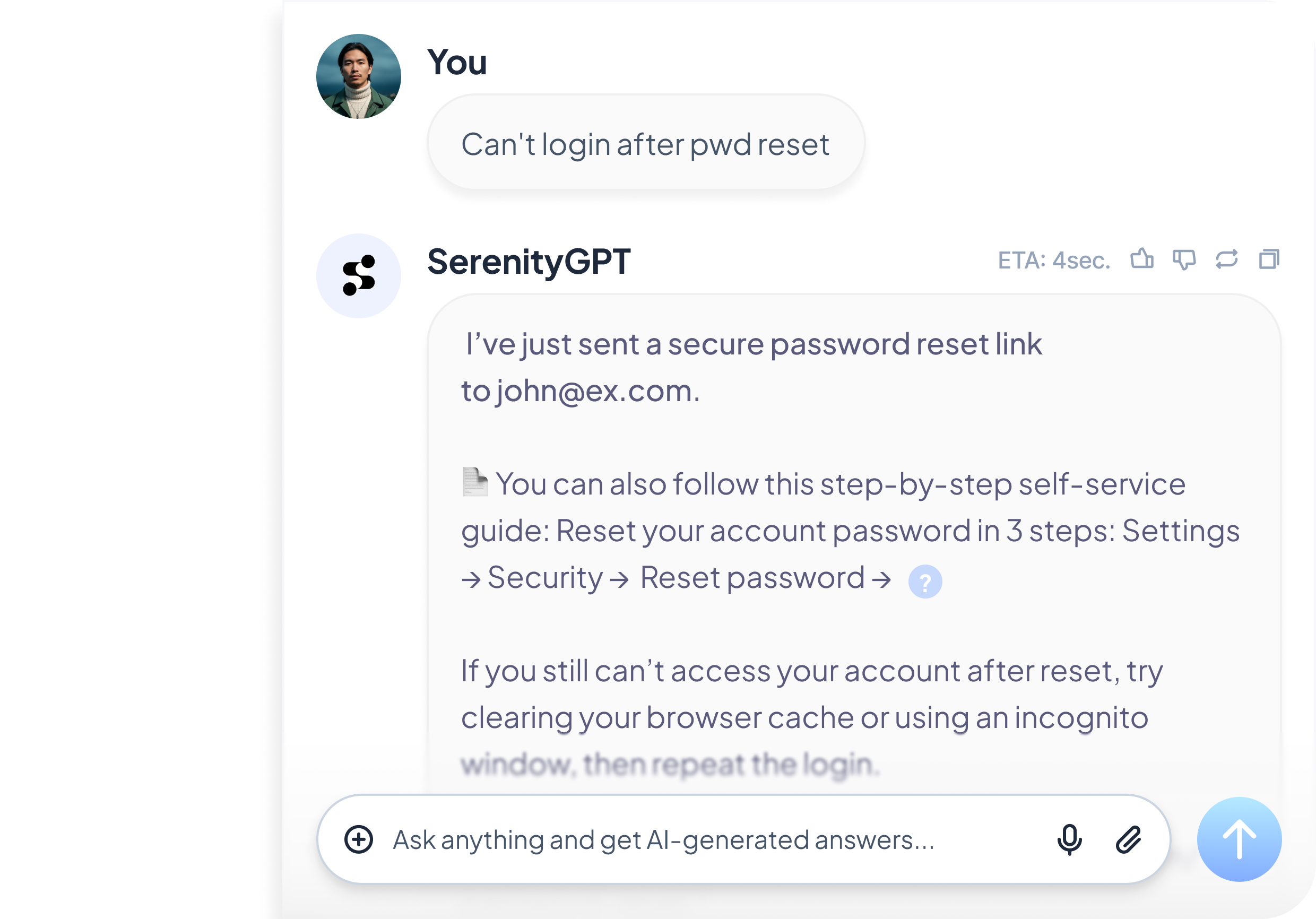
Answers in Seconds, Not Hours
Employees ask questions in natural language and get accurate, sourced responses instantly. SerenityGPT connects your wikis, documentation, ticketing systems, and tribal knowledge — so the right information is always at your team's fingertips.
Knowledge & Automation for Every Team
Modular value stack: Semantic search, agentic automation, secure indexing—proven 50% ROI from day one.
Resolve Faster. Automate More
Agents get instant answers from your knowledge base. AI handles ticket routing, suggested responses, and auto-resolution of common issues. Reduce handle time by 40% and let your team focus on complex cases.
- 40% faster resolution,
- 60% auto-handled tickets.
Built for Your Industry
SerenityGPT helps support teams deliver fast, accurate answers and run repeatable workflows, grounded in your approved knowledge and ticket history. Customers get reliable self-service. Agents get confident assistance. Leaders get visibility into what drives volume and friction.
see moreFrom connection to confidence in weeks, not quarters
Connect your sources
Docs, help center content, ticket history, CRM, and internal portals.
Apply permissions and guardrails
Respect access rules, define what content is "approved," set escalation paths.
Deploy where work happens
Web, Slack/Teams, help desk, CRM, intranet, or embedded widgets.
Improve continuously
Feedback loops, analytics, & content gap suggestions to keep answers sharp.
One platform, multiple ways to deploy

Assistant
- Ask questions in plain language
- Get answers grounded in company knowledge
- Share results in the tools your team already uses

Knowledge
- Organize and standardize what "correct" means
- Keep critical content current and discoverable
- Reduce conflicting answers across teams

Insights
- See what people ask most
- Spot content gaps and process bottlenecks
- Track adoption and operational impact

Agents
- Turn common requests into guided workflows
- Reduce manual handoffs and repetitive steps
- Keep actions consistent with business rules
Enterprise-ready security and governance
SerenityGPT is designed to fit into existing security and compliance programs.
Access and identity:
SSO, role-based access, user provisioning (if applicable)
Data protection:
encryption in transit and at rest, configurable retention
Governance:
audit logs, admin controls, approval workflows for sensitive use
Model control:
configurable model options and data handling preferences

Works with the tools you already use
Connect SerenityGPT to the systems where knowledge lives and work happens.